If you have a problem with memory bloating or leaks, the tool of the first choice is Valgrind. Briefly, it wraps some standard library calls with their implementation (malloc, new, etc.) and tracks all memory allocation within your code. By default, Valgrind is checking whether all memory allocated in the program is freed at the end. A more sophisticated tool is massif – it collects all allocations to profile memory consumption over time. After the program run, you may check it with ms_print or massif-visualizer GUI.
During my last job, I’ve noticed, that my application’s memory is constantly increasing. I’ve run Valgrind massif to check why. Unfortunately, I couldn’t find the reason, since all stacks were empty. All I could see was the amount of memory consumed without stack traces. Listing below shows the ms_print output
As you can see, there are no stacks collected. I spent two days investigating what’s going on. I will not write about the whole process, but I have eliminated the most obvious tracks like debug symbols, compiler options, etc. The last thing was reading the docs. I found these options:
--unw-stack-scan-thresh=<number> [default: 0] ,
--unw-stack-scan-frames=<number> [default: 5]
Stack-scanning support is available only on ARM targets.
These flags enable and control stack unwinding by stack
scanning. When the normal stack unwinding mechanisms -- usage
of Dwarf CFI records, and frame-pointer following -- fail,
stack scanning may be able to recover a stack trace.
Note that stack scanning is an imprecise, heuristic mechanism
that may give very misleading results, or none at all. It
should be used only in emergencies, when normal unwinding
fails, and it is important to nevertheless have stack traces.
Stack scanning is a simple technique: the unwinder reads
words from the stack, and tries to guess which of them might
be return addresses, by checking to see if they point just
after ARM or Thumb call instructions. If so, the word is
added to the backtrace.
The main danger occurs when a function call returns, leaving
its return address exposed, and a new function is called, but
the new function does not overwrite the old address. The
result of this is that the backtrace may contain entries for
functions which have already returned, and so be very
confusing.
A second limitation of this implementation is that it will
scan only the page (4KB, normally) containing the starting
stack pointer. If the stack frames are large, this may result
in only a few (or not even any) being present in the trace.
Also, if you are unlucky and have an initial stack pointer
near the end of its containing page, the scan may miss all
interesting frames.
By default stack scanning is disabled. The normal use case is
to ask for it when a stack trace would otherwise be very
short. So, to enable it, use --unw-stack-scan-thresh=number.
This requests Valgrind to try using stack scanning to
"extend" stack traces which contain fewer than number frames.
If stack scanning does take place, it will only generate at
most the number of frames specified by
--unw-stack-scan-frames. Typically, stack scanning generates
so many garbage entries that this value is set to a low value
(5) by default. In no case will a stack trace larger than the
I’ve set --unw-stack-scan-thresh to 5, because all stacks had 0 or 1 element. --unw-stack-scan-frames to 30 – I don’t use recursion, so this value is much above needs. After setting it up the stacks appeared in ms_print output. Apparently, normal stack resolving failed – why? Maybe it’s because old gcc – 4.9.2 version. Another possible reason is that the standard stack parser works only on x86 architecture.
I didn’t spend much time finding out why this option was needed. If you know why, please share your thoughts in a comment.
One of the key features of C++ is operator overloading. Beginners might find it difficult since the syntax is not intuitive. In this article, I will show you how to omit typical problems in this case.
In my last project, I had to operate on large XML files – read and write some values under specific XPath locations. during development, I have used libxml2 library. It has a really complicated C-based interface, so I had to create a convenience wrapper class.
I used C++ so I decided to use the index operator to fetch values under a specific key. The first interface looked like the following:
class XmlWrapper
{
public :
//...
std::string operator[](const std::string &key) const; //getter
std::string& operator[](const std::string &key); //setter
//...
};
What is wrong with this approach? At the first sight, it might look ok, but if you start implementation of setter, you will find out, that changing the content of the in-memory libxml2 tree is impossible. The upper approach would be ok if we would change the class attribute of type std::stringdsdf. Otherwise, this approach fails.
What is the possible solution to this approach? I used a proxy class design pattern. Before I will show you the code I will write down, what were the goals of the solution.
Access in-memory XML tree with setter to modify its content
Assign results of getter bracket operator to the std::string variable without intermediate steps.
Like point 2, but the other way assign to setter type std::string.
To implement goal 1, we must have some connection with XML-tree. String class obviously doesn’t. So the returned proxy class has the reference to XmlWrapper holding libxml2 instrumentation. To implement goal 2 we will implement cast operator from proxy class to std::string. To implement goal 3, we will do a similar thing – overload operator = with std::string parameter. The solution looks like this:
class ProxyXml; //forward declaration
class XmlWrapper
{
public :
//...
const ProxyXml operator[](const std::string &key) const; //getter
ProxyXml operator[](const std::string &key); //setter
//...
};
class ProxyXml
{
//...
operator std::string() const;
ProxyXml& operator=(const std::string &s);
protected :
XmlWrapper &xml_;
};
If we want to access XML content for read, the code creates a temporary ProxyXml object, and convert it to std::string class. If we want to modify XML content we create ProxyXml and use its XmlWrapper reference inside operator=. Sample usage looks like this:
With this article I am starting the large series, telling how precisely the Linux kernel works. Me and my readers will investigate each line of kernel code from the beginning, to a fully operable system. Hopefully, it gives us a strong foundation of Linux knowledge. I expect from you the C programming knowledge and computer architecture basics however, I will try to simplify more complicated statements, to keep less experienced readers here. As my article describes kernel code, I will frequently refer to git repository content. My suggestion is to clone the whole repo from https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git and checkout to da2968ff879b9e74688cdc658f646971991d2c56 commit (the one I’m working on).
The kernel has many ports to different architectures. Telling about startup and running kernel is hard without describing whole booting process. To keep the article simple, without non-checkable abstractions I will tell you about the BeagleBone Black booting sequence. It is open-source board – schematics is right here https://github.com/beagleboard/beaglebone-black/blob/master/BBB_SCH.pdf – which contains ARM-based TI AM335x family microprocessor – AM3358. We can find its reference manual easily (https://www.ti.com/lit/ug/spruh73q/spruh73q.pdf). I will refer to these documents frequently. We have everything ready, so let’s get started.
Powering up
The story begins by powering up the device. When the voltage is turned on, PRCM (Power, Reset, and Clock Management) module detects it. This module is a central unit of power management. It decides to turn on or off voltage on electronic domains and start or stop clocking them. All the details about it are described in Chapter 8 of Reference Manual – PRCM. It includes a lot of information since this module handle functionalities such as low-power modes, different types of reset, etc. We will not cover all of them, since it is not the topic of this article. Our ARM Cortex A8 Core belongs to MPU (Microprocessor Unit) subsystem, which is quite complex and covers several Power domains – details are described in Chapter 3. For some reason, there is a split MPU power domain (Cortex A8 core, cache memories, some other modules such as IceCrusher) and Core power domain (which includes Interrupt Controller).
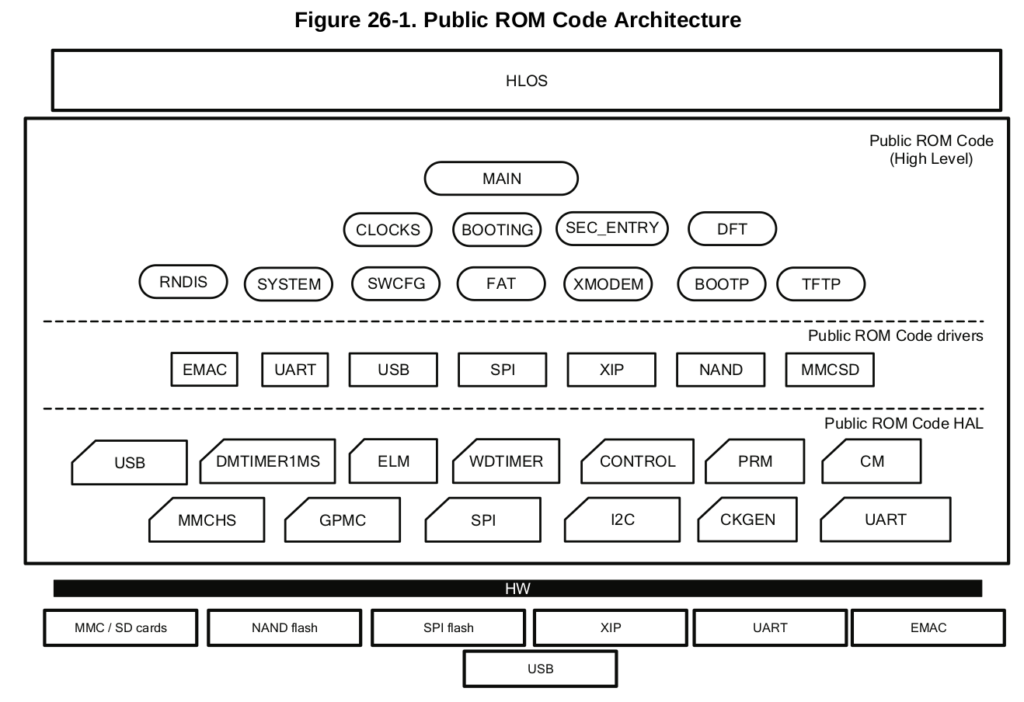
ROM Code
I will not cover electronic details, since it is not the essence of this article. The key point is that only the most important parts of our processor are powered up and supplied with the clock signal. Reset exception redirects CPU to non-erasable on-chip memory, written by silicon vendor (TI). As a consequence, the so-called, ROM code is started by our micro. It is the only part of the boot sequence, executed by not open-source code, but we can find a huge amount of information about it in Reference Manual and on the Internet.
Boot ROM memory offsets
Boot ROM memory is addressable directly by our micro with an 0x4000 0000 offset. All the addresses presented on the upper photo should be prefixed with 4 on the most significant digit, like in the picture below. Why they are not? During early startup, ROM may be accessed through alias address, without leading 4. So it may operate on 0x0000 0000 0x0002 BFFF space.[1]
Boot ROM entry in main memory map
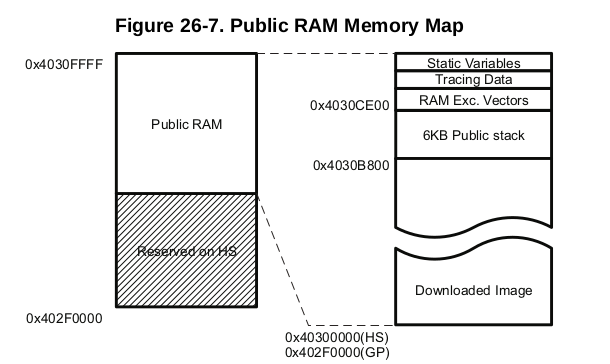
Boot ROM has some advanced features, like peripheral booting or checking image signature. It needs some operational memory. At this, early-stage the only one is internal static RAM:
Internal SRAM memory map
The answer to how much of this is usable depends on the type of device. It might be GP (General-Purpose) with the secure boot features disabled, or HS (High-Secure), which do not allow to boot untrusted code. The latter of course need more operational memory during ROM Code execution.
First, 1kB is reserved on both types and could not be used. Next 109 kB (on GP) or 46 kB (on HS) is the place where the next part of the boot chain (SPL) is copied by ROM Code. The last 18 kB is general-purpose operational memory used at this stage (more info on the diagram below). For the sake of simplicity, I will cover GP device boot.
Let’s get back to the place where we begin. When our micro is powered up, it starts execution from Secure Boot ROM – maybe from address 0x0000 0000. There is not much information about this process. Only that it uses ARM TrustZone architecture to obstruct reverse engineering. We can deduce, that layout of Secure Boot ROM is similar to Public Boot ROM (own exception vectors, CRC, code, and version). We will not focus on it. The only valuable piece of information is that the first 128 kB of ROM is reserved and it is executed on the earliest startup.
ROM Code Exception Vector – reset entry
First public information is that after Secure Boot ROM execution, code jumps to public exception vector, which in turn redirects execution to Public ROM Code (0x4002 0100, aliased with 0x0002 0100). On the initialization phase, the stack is set up in Internal SRAM, ROM Code CRC is calculated, and checked against address 0x4002 0020 to detect eventual memory issues. The watchdog WDT1 is started and set up for three minutes. Exception vector base is redirected to Public Boot ROM, so any exceptions are now handled by it. Then the first configurable part is done – setting up clocks.
Clock configuration
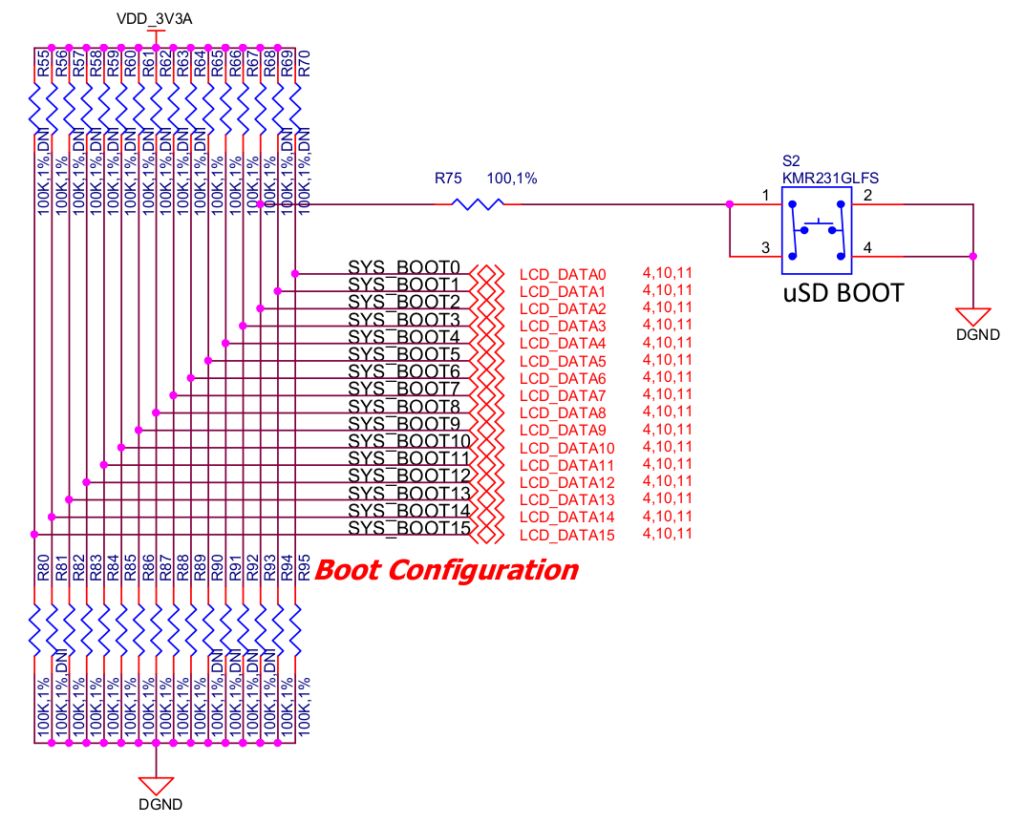
The clocks are configured for their default values. To do this, the board creator must inform Boot ROM code, what crystal is used. It is done with hardware configuration using SYSBOOT pins.
Supported crystals and SYSBOOT pins to configure the right one
Now let’s check what crystal is placed on BeagleBone Black schematics and how SYSBOOT is configured.
OSC0 wiring
Boot configuration pins on BeagleBone Black
As we can see, the main oscillator (OSC0) is connected to a 24 MHz crystal, and as the manual says SYSBOOT pins are wired to logical 1 (14) and logical 0 (15). You may wonder why there are pull-ups and pull-downs added to the schematics on each line. I think it is to make eventual changes easier. Every pull-up has DNI annotation, which I suppose stands for Do Not Integrate. So the R80 resistor pulls down the voltage for SYSBOOT 15 pin and R56 pulls up SYSBOOT 14. R55 and R81 should not be soldered on the board.
According to these settings Public ROM code configures default clocking rates of essential devices. You can find them on the diagram below:
The peripheral clocks list is not accidental – it contains all the devices which allow chaining next parts of boot sequence – SPI memory, MMC card, UART, USB. These are a possible source of the Secondary Program Loader – which will be described in one of the next parts. (MPU_CLK sets core clocking, L3F is one of the internal silicon buses, I2C I suppose is used to check the voltage conditions. I think the EMAC clock should also be listed here).
Boot chaining
Now the Boot ROM is going to the essence of its existence. It starts searching for the next elements of the boot chain – Secondary Program Loader. It will be described in one of the next parts of this series. For now, let’s look at how ROM Code searches for it. SPL is the first program executed by chip, coming from outside the AM335x processor. The board creator must choose the right booting device list (using SYSBOOT pins), to tell ROM code, where SPL should be placed. This process is similar to setting up PC BIOS booting sequence. If one device will not contain it, the next one is taken from the list.
AM335x allows booting from memory (like MMC or internal NAND) or peripherals (UART, Ethernet, or USB). If all of the sequenced boot methods fail, ROM Code goes to one of the dead-loops (0x20080 offset). All possible SYSBOOT combinations are described in table 26-7 of Reference Manual. It is too big to paste it here, however below you can find entries, which are used on BeagleBone Black. During this series, I will use and describe external SD card boot (MMC0), to easily update new firmware and follow kernel on it :). If you want to read more about other types of boot devices, please check the Reference manual, chapter 26.
BeagleBone Black boot options
The first combination begins to boot from MMC1 (soldered 4GB embedded MMC memory). If there is no image written on eMMC, the MMC0 interface is examined, wired with the micro SD slot, which will be supplied with our SD card:
If there is no image on eMMC, then both scenarios are almost the same. We will boot from an SD card. However, if it’s not empty, we must push the uSD BOOT (S2) button, when powering up. It will pull-down the voltage on SYSBOOT 2 and force the second boot scenario – examining SPI memory (which is not attached and fails), and then the MMC0 interface. The last two options (UART/USB) are not considered, since we will supply the board with a correct image on the SD card.
MMCSD
MMCSD controller in our AM335x processor is flexible enough to handle communication with a micro SD card. There is a lot of information about MMCSD controller communication in chapter 18 of the Reference Manual. The protocol used with SD cards is quite simple. There is a clock signal (MMC0_CLK), which allows transfer through 4 data lines (MMC0_DAT0-3). Data transfers are controlled by commands, serially sent through the MMC0_CMD line. MMC0_CD is a card detection line. As you can see on the schematics, it is pulled-up to 3,3 V. If the card is inserted, mechanical switch wires this line with grounded housing, and drives this pin low. According to documentation, Boot ROM Code does not use it, but sends a command and waits for a response instead. It is reasonable, since the polarity of this signal may vary among different boards.
MMC initialization is quite complicated because it covers different standards of memory storage. MMCSD controller supports MMC memories (8 data lanes), SD cards (4, 1 DAT lane or differential transfer on UHC-II) with different size and transfer rates. The transfer might use Single Data Rate or Double Data Rate – data clocked on rising and falling edge. All these details must be figured out on the command line. The protocol used there is compatible with all standards. Data packets are sent there serially in 48-bit requests. The first two (01) creates start sequence, next 6 are the command number. Right after that, 4 bytes of argument is passed. The packet is ended with 7-bit CRC and stop bit. Command numbers are described in manuals as CMDXX, where XX is a 6-bit command number. Sometimes they are prefixed with ACMDXX, which stands for Application-Specific Command. The response might be 48 or 136-bit, depending on the request type.
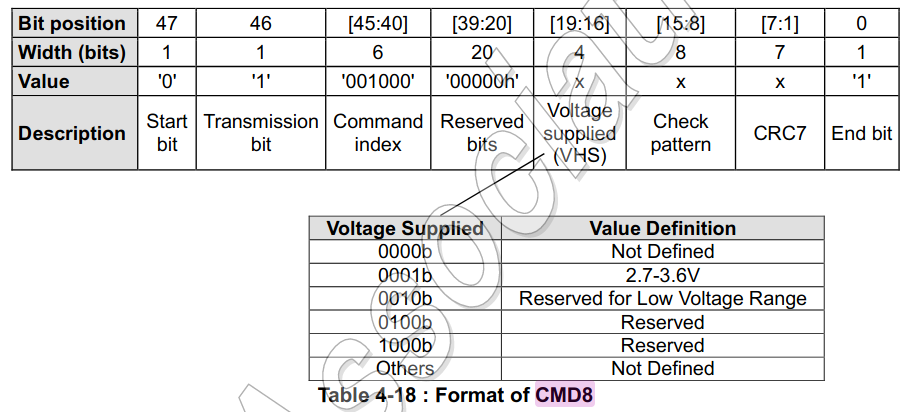
MMC initialization probably starts with CMD0 – the card chip reset. I haven’t checked the sequence, however, I assume it’s safer to make sure, that card is in an idle state. In the idle state, the default 400kHz rate clocks commands and responses, which should be supported by all standards. The next command strongly depends on card type, so I will focus on SD standard. So the CMD8 is sent to determine if current voltage conditions are OK for the card. It also tells whether the card supports SD standard in version 2.0 (this command was declared there). If there is no response for it, the controller knows, that card is in an older standard.
Let’s assume, that response was correct – with the same value in the VHS field and check pattern. The next command is ACMD41. It is an Application Specific command (preceded by CMD55), which starts the initialization process. The host sends suggested configuration bits (HCS, SDXC Power Control, S18R) and check if these settings are supported by the Card. If the settings are not supported, the card goes into an Inactive state, and the whole initialization must be repeated. Otherwise, the card sends a response with OCR (Operational Conditions Register) value. It contains a busy bit that is set if card chip initialization is completed, or it is still ongoing. In that case, ACMD41 must be repeated to poll the initialization. All configuration bits are presented on the diagram below. With HCS, the host declares its support of High Capacity or eXtended Capacity conformance. If the SDXC standard is supported, Card might be put into power saving or fast mode with XPC. UHC-I standard also allows switching logic voltage to 1,8V (shorter edges and faster data transfers). It might be checked with the S18R bit and activated with CMD11 later on.
Card responds with configuration bits and current Operational Condition Register value in this format:
After this handshake, the host and card know which standard will be used during later communication (Data Transfer Mode). The next phase is Card Identification Process. All previous commands were sent in broadcast addressing, now the host must allocate an address for each card connected to the bus. To do that, it issues CMD2, as a response Card sends its Identification Number (CID). This triggers Identification State on the Card. Next CMD3 is sent by the host. As a response Card suggests a shorter Relative Card Address (RCA). If the host accepts it, in later communication card will be identified with this RCA Address. If the host does not accept it, it must repeat CMD3.
As you may notice, a card address assignment is needed. It implies, that this interface support connecting many cards on that interface. We will not go too deep into it. The important thing is that RCA is used during Data Transfer Mode, which started right after CMD3. Now we can request data read, write, or card erasure, using yielded RCA.
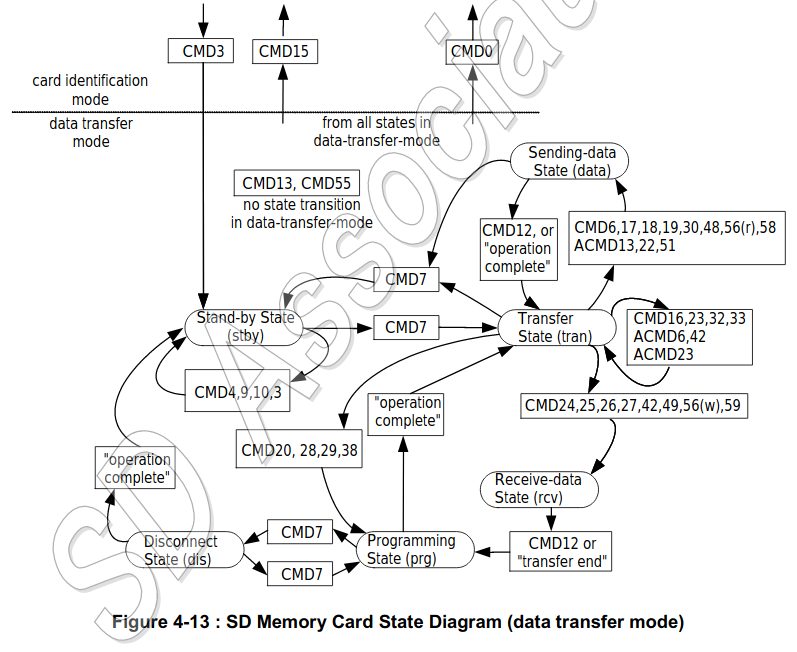
To do that, we must transit the card chip from the Stand-by state (in Data Transfer Mode) to the Transfer state, using CMD7. Of course, we must supply RCA argument to this request. Other cards on the bus are transitioned to a Stand-by state (if it is in Transfer mode). The whole state diagram of the Data Transfer Mode is placed below.
After triggering the CMD7 command our card is in Transfer State. By default, data transfers are made on a single DAT0 line. To extend it, we send ACMD6 request with 10b argument.
At this moment distinction between SDSC (Standard Capacity) and SDHC/XC (High Capacity/eXtended Capacity) must be made. The first group could change block length (data are sent in blocks) and could address data using bytes – but has less capacity. The latter have extended capacity, but it is always addressed using block number, which is always 512-byte sized. After this short setup, we can access our data with CMD17 (single block read) or CMD18 (multiple block read). CMD18 transfer is finished with CMD12 (stop transmission).
This state machine and read process is managed by the MMCSD driver inside ROM Code. Right above that we need some logical data structure to gather the SPL. There are several ways, we can put SPL (later named as MLO – MMC Loader) in the SD Card. The first is Raw mode – MLO is directly written on the SD Card in four copies (0x0, 0x20000, 0x40000, 0x60000 offsets), without the usage of any file system. There is also an option of writing a file called MLO in the active, FAT partition. This is the way which I will cover. In this case, FAT module handles logical memory structure.
Reference Manual presents the layered structure of ROM Code. On the top of the MMCSD driver, the FAT module is used to access data in a formatted SD Card if we use this file system.
MBR
The card can be formatted with the so-called Master Boot Record (it allows putting several partitions on the card), or whole memory may be formatted with FAT. The first approach will be used, so the first sector on our memory is a Master Boot Record (MBR). This is the logical structure, telling about partitions present on the memory and specifying their details like name or usage flags (active/not active, boot partition). The job for ROM Code is to find active FAT 12/16/32 partition with MLO file in its root folder. The structure of the MBR is presented below.
The first thing done is to recognize, if a sector is indeed MBR. To do this, the signature at the end is used. It must be equal to 0xAA55. Right after that, partition entries are examined whether any of them contains the FAT file system and it is active. There is an obvious error in the Partition End Head position – it has a 1-byte length, not 16 like on the diagram below.
This structure gives information about the placement of the partition on the SD Card. It might be written in two ways, using CHS (Cylinder Head Sector) way on 3-byte addresses (start at offset 1, end at offset 5). Or it might be specified using 4-byte LBA (Logical Block Addressing) – start at offset 8, size of the partition at offset 12. According to these data, we can check if the MBR entry is not malformed (address goes outside available memory) and move further.
FAT File System
FAT stands for File Allocation Table. It is the second logical part of this file system, after the Boot Sector, which includes BIOS Parameters Block and before Root Folder and Data Area. Boot Sector is placed on the first sector occupied by partition. Important for us is that it contains much information about file system structure:
Bytes per sector – in the flash drives it should be the same as block size since it is the smallest erasable piece of memory. Usually, it is equal to 512.
Sectors per cluster – FAT makes from whole Data Area small parts, called clusters. We could see it as the smallest allocation area. Each cluster is assigned to a single file and a single file may lay in several clusters distributed among the whole data area.
Position of the Root directory – it is not directly written in BIOS Parameters Block, but it may be calculated from parameters given there.
Number of sectors per Boot Sector
Number of FAT copies (to prevent data malformation FATs are usually duplicated)
Absolute position of the FAT partition in flash memory space
After the Boot Sector, there are File Allocation Tables. This is a register of all clusters used by a file system. The offset of the FAT cell tells, to which cluster in Data Area it is assigned (offset between start of FAT and cell position, corresponds to offset between Cluster and start of Data Area). FAT cells create a structure of a singly linked list. Each file has assigned HEAD of this list – which is the offset of the first FAT cell used by this file. This FAT cell is assigned to a cluster at the beginning of the file and it contains the offset of the next FAT cell used by this file. If the file is small enough to fit into one cluster, the list contains one cell with the value 0xFFFF. If the file is bigger than the cluster, the cell value is the offset of the next one (for example 0x0010). If the cell under offset 0x0010 contains 0xFFFF, the file is written in two clusters.
It’s quite simple, but where is the information about head cells assigned to files? The heads of files placed in the root directory are placed in the Root Folder part. As I mentioned, it is statically addressed. This address may be calculated from BIOS Parameter Block. Our MLO file must be placed there, so I will not tell you about the subdirectories structure. Root Folder contains up to 511 entries, which structure is described below:
Boot ROM Code focuses on checking if the file is called MLO and it has correct attributes (not hidden file). According to this FAT Directory Entry and File Allocation Table look-up, we can easily access MLO file data. This is the thing, done in the next step.
Using MMC and FAT file system implies, that we must Shadow the MLO code. The shadowing is copying data into another place (RAM), from it could be easily executed. AM335X allows also the use of XIP (eXecute In Place) memories, which could avoid it. But I only give you it as nice curio.
Running the code
The MLO file, using FAT and MMC layers, is parsed and the image included there is copied to the 0x402F0400 address (it is placed in the internal Static RAM). For Secure devices this address is different and the available area is smaller.
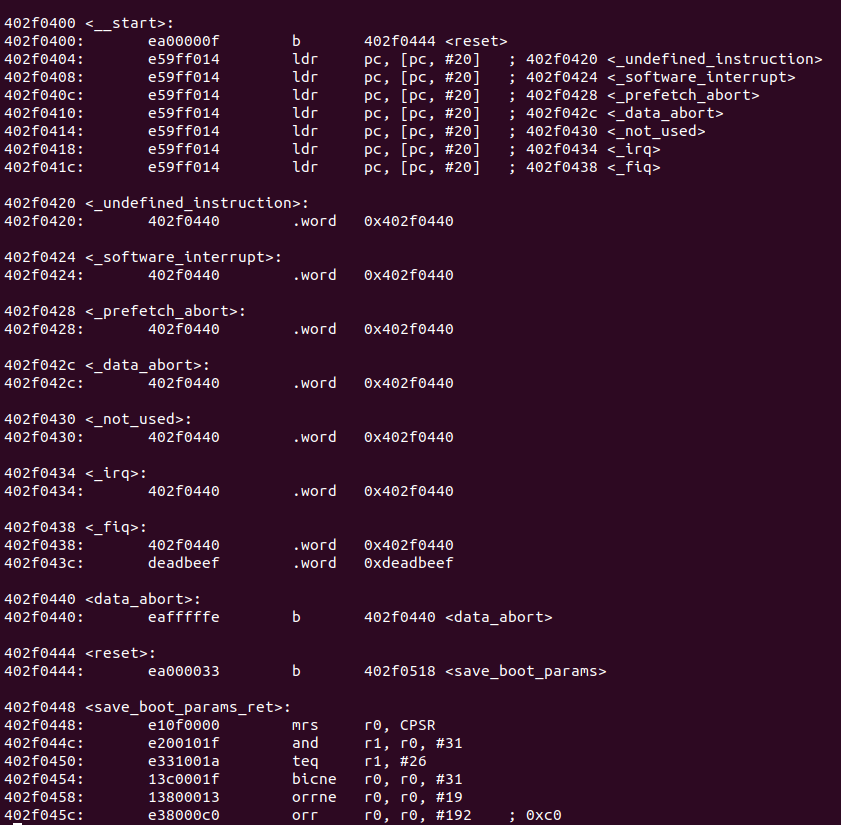
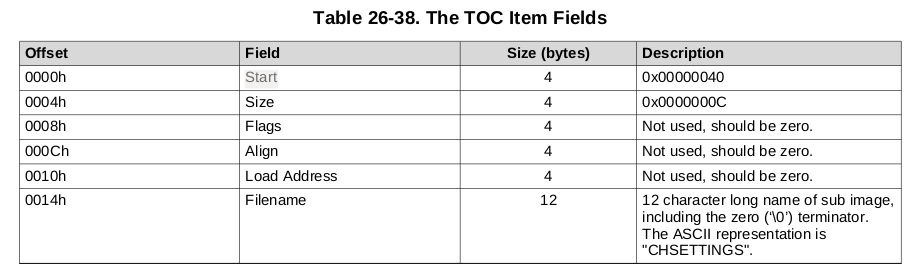
It took me some time to resolve the MLO file structure. It is a generic file format, which is not fully used here. In the beginning, we can find two 32-byte so-called Table Of Contents entries. The first word in it is offset of described entry, the second is the size (like on table 26-38). The next 12-bytes are not used by us. At the end of the TOC entry, we have a section name, which is CHSETTINGS. The last TOC entry must be filled with the FF, that is why we have FFs between 0x20-0x40 address.
HEX-decoded MLO file (0x00-0x20) is first TOC entry. 0x20-0x40 second one. Under 0x200 you can find size, destination address and first instruction of SPL code – branch to reset routine.Disasembly of the SPL code (0xea00000f instruction can be easily found under 0x208 offset on upper screenshot).
According to the documentation, TOC is required when booting from MMC/SD in RAW Mode. MLO which I have also have this preamble, however. TI documentation doesn’t say much about the purpose of this beginning. We know, according to MLO code (more on that in next chapters), that the first TOC entry points to settings structure, which looks like this:
CHSETTINGS structure
TOC entries and their content takes first 512 bytes of MLO. Under offset 0x200 GP Device Image format starts, its structure is presented below (under HS device it looks different).
Under offset 0x200 of MLO, there is a size of the image to be shadowed (copied). I’m not sure, why the Destination address is supplied (offset 0x204) because the image is always copied into the same area, which may vary only between GP/HS devices. Maybe it is caused by Image unification between TI platforms.
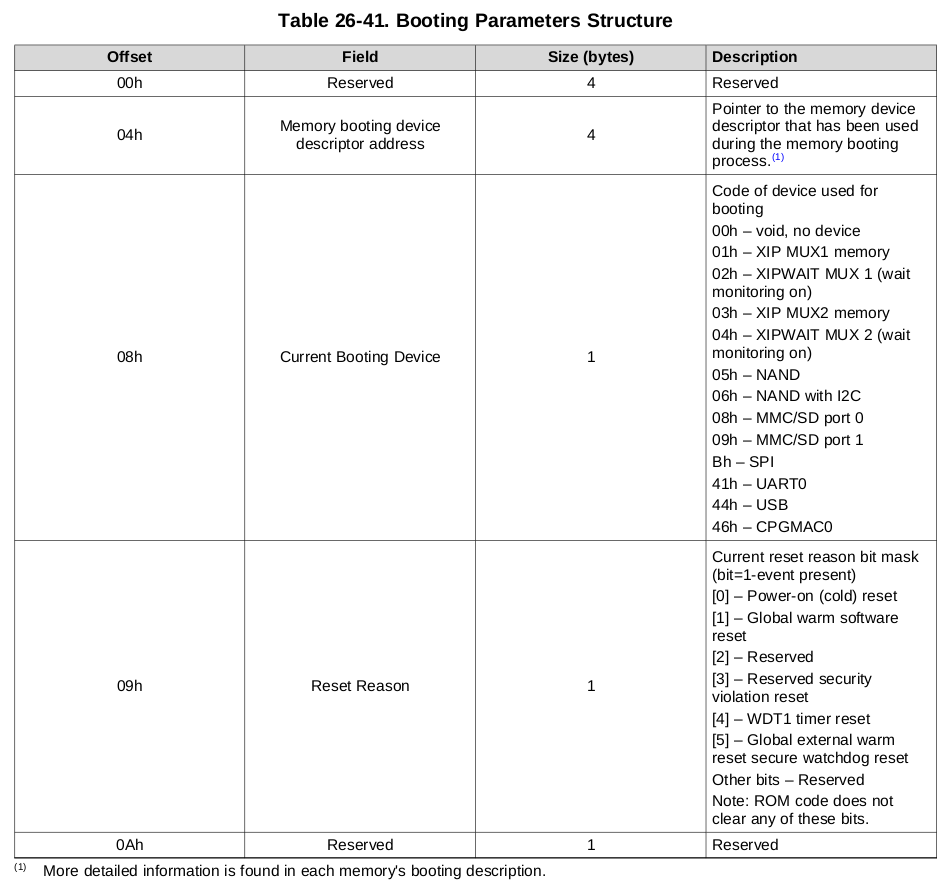
The last and most important part is the Secondary Program Loader code. It is copied directly to internal SRAM. On the upper screens, you have seen the first line of the code, which is placed right there (offset 0x208 MLO) – branch to reset routine instruction (0xea00000f). Only this part of MLO is copied to the 0x402F0400 address. After successful image load, Program Counter is placed right there. ROM Code leaves some information about boot device and reset reason in a structure presented below. Pointer to this structure is passed in R0 register..
Summary
When I started this article, I had a completely different concept. I thought, that one article will be sufficient to describe Boot ROM Code, MLO, U-Boot, and head of the Linux kernel. I have noticed, that the topic is much deeper than I thought, and the first part allowed me to create this long article. I’m really happy about that because I found a lot of new information, which hopefully will be new for the readers also.
We could start the next chapter from the topic I already mentioned – MLO Code, however, I think that a better idea will be focusing on Kernel Build System. It is common for the U-Boot, Linux and some other projects. It uses mainly Makefile scripts. The knowledge on it will give us strong foundations before diving into the code.
I hope it will be shorter article because the next one will be much more interesting
The difference in using stdatomic is obvious, so let’s check how ARM compiler works to make it happen. The first assembly code is generated from non-synchronized.c file:
Code is quite similar to x86. The most crucial part is L7, which implements addition, and L5, which implements subtraction. Let’s see what they are doing:
movw r3, #:lower16:x /* Load less significant 16 bit of x address */
movt r3, #:upper16:x /* ... and more significant part */
ldr r3, [r3] /* Load value of x to r3 register */
add r2, r3, #1 /* Add 1 to x (sub in L5) */
movw r3, #:lower16:x /* Put address to register (like previously) */
movt r3, #:upper16:x
str r2, [r3] /* Store result */
We can see, that this code is longer than its x86 counterpart. Now let’s see how arm-linux-gnueabihf stdatomic implementation looks like:
This time, synchronized implementation is much more complex, but it’s not a problem for us :). After short initialization, the code jumps to L4 code, where for loop is implemented. If the break condition is false, the code jumps to L11. L11 in turn starts with examining arg parameter against NULL (check code in part #1). If it’s not, L11-L6 code makes the addition otherwise, the jump to L5 is made. If you compare code in L11-L6 and L5-L9, you can see, that they are almost the same:
Data Memory Barrier acts as a memory barrier. It ensures that all explicit memory accesses that appear in program order before the DMB instruction are observed before any explicit memory accesses that appear in program order after the DMB instruction.
The dmb instruction has the second part, defining which operation should unlock our barrier. In this case, we are locking till the whole memory subsystem finishes its job (sy). It ensures so-called Sequential Consistency. It is done before ldr instruction (which as str, should be considered as asynchronous) loads current x value, to make sure, that all stores called before were done (in other words, whether we load most actual value).
After finishing ldr operation (which is synchronized with second dmb sy), we are storing a loaded value to local copy on the stack (fp-28 in addition branch and fp-16in subtraction branch). Keep in mind, that only accessing variable shared by both threads is surrounded by dmb instructions.
L8 and L10 blocks load the value of x to r2 register, then value 1 to r3 and adds (or subtracts) them, saving the result in r3. After that result is stored in the new place – fp-24 in addition branch and fp-12 in subtraction branch. The result is also moved to ip (r12) register. Right after that, r3 register once again is filled with x address, r2 is filled with fp-28 (fp-16). Let’s go back to the previous paragraph – these locations are our local copies of x value, which are loaded to r0 register. Keep in mind that this value was not changed by our addition (subtraction) operation.
Then the comparison between r1 (value of x) and r0 (local copy before operation) is done. If these values are not equal, it means, that someone changed x during our L8(L10) execution. Let’s analyze this case – we are jumping to L14 (L15). This block is not intuitive at all – it synchronizes memory operations, loads 1 to r3 if our previous compare was true (not this time), and loads 0 otherwise (this case). Then it compares r3 against 0 (we loaded 0 just before – true) and calls bne to L6 (L9), which in our scenario is not done (bne is “branch if not equal”). ARM is known of conditional instructions, it is nice, but puzzling it in such context is not easy :). We didn’t make a jump, so we are storing r1 (x value) to address under r2 (or local copy). After that cmp + bne + b set moves our instruction pointer to L8(L10) and all described operations are repeated. Not efficient :(.
Now let’s go back to cmp r1,r0 and consider, that these values didn’t change. In this case, we are storing our result with strex in a shared x location. strex stands for store exclusive, so we can expect some kind of synchronization – probably dependent on ldrex usage. It stores our changed value in a shared x value address and returns the result to the lr – a synonym of r14 – register. If the store is successful, it returns 0, and our execution path goes to L14(L16). The previous paragraph puzzled this code, in this case, we are finishing in common L7 block, which prepares next for loop step. If the store failed, we are repeating L13 (L15) once again.
Could you write it simpler?
Yes :). I prepared some pseudocode, describing this assembly listing. Here you have:
l_1 <- 1
------ Memory barrier
r3 <- x
------ Memory barrier
r3 -> l_x
L10:
r2 <- l_x
r3 <- l_1
r3 <- r2 +/- r3
r3 -> l_res
ip <- l_res
r0 <- l_x
------ Memory barrier
L15:
r1 <- x /* exclusive */
if (r1 != r0) goto L16
ip -> x /* exclusive wit result to lr */
if (lr != 0) goto L15
L16:
------ Memory barrier
if (r1 != r0) goto L10
l_x = x;
l_1 = 1;
start:
l_res = l_x +/- l_1;
storing:
if (l_x != x(ex)) /* exclusive x load */
{
l_x = x;
goto start;
}
else
{
/* exclusive store returning 0 if succeed */
if (x =(ex) l_res)
goto storing;
}
l_ prefix stands for a local variable copy. Exclusive operations (strex and ldrex) are marked with (ex). If you didn’t get my assembly analysis, you should focus on C-like pseudocode.
The thing, which does the job in this program is ldrex and strex instructions. This couple allows atomic load-modify-store operation via the so-called “Exclusive monitor”. ldrex instruction initializes its state machine and tells it to wait for the following strex. If any context switch happens between these two steps, which may corrupt atomic operation, strex will return 1 into lr register. In this case, ldrex + strex operation must be repeated. If this context switch also changed the value of x, the whole calculation done before must be repeated with the current value (goto start).
Memory barrier
I found on the internet some opinions, that dmb instruction is only needed on multi-core processors. I was curious, whether it is needed in our context (TI AM3359 single-core processor) or not. To check this, I have removed all memory barrier instructions from assembly and compiled a new version:
My test shows, that these barriers are redundant however, I’m not sure if corruption, in this case, is not possible or not likely.
Summary
This code is complicated, comparing to the x86 implementation. It may be due to the old gcc version. However I suppose, that ARM instruction set is focused on low power usage and that is the main reason. I made some measurements of execution time. To make it more reliable, I should change for loop to a longer run, but I will leave it as an exercise for the reader 🙂
$ ##### x86 :
$ time ./non-synchronized
708439
real 0m0,011s
user 0m0,017s
sys 0m0,004s
$ time ./non-synchronized
-998811
real 0m0,009s
user 0m0,016s
sys 0m0,000s
$ time ./non-synchronized
986583
real 0m0,011s
user 0m0,015s
sys 0m0,004s
$ time ./synchronized
0
real 0m0,039s
user 0m0,068s
sys 0m0,004s
$ time ./synchronized
0
real 0m0,053s
user 0m0,097s
sys 0m0,008s
$ time ./synchronized
0
real 0m0,053s
user 0m0,103s
sys 0m0,000s
# ##### ARM Cortex-A8
# time ./non-synchronized-arm
-396494
real 0m 0.07s
user 0m 0.04s
sys 0m 0.00s
# time ./non-synchronized-arm
0
real 0m 0.08s
user 0m 0.03s
sys 0m 0.01s
# time ./non-synchronized-arm
-531472
real 0m 0.07s
user 0m 0.04s
sys 0m 0.00s
# time ./synchronized-arm
0
real 0m 0.56s
user 0m 0.34s
sys 0m 0.00s
# time ./synchronized-arm
0
real 0m 0.56s
user 0m 0.33s
sys 0m 0.01s
# time ./synchronized-arm
0
real 0m 0.54s
user 0m 0.34s
sys 0m 0.00s
# time ./synchronized-arm-no-barrier
0
real 0m 0.12s
user 0m 0.06s
sys 0m 0.02s
# time ./synchronized-arm-no-barrier
0
real 0m 0.09s
user 0m 0.07s
sys 0m 0.01s
# time ./synchronized-arm-no-barrier
0
real 0m 0.10s
user 0m 0.07s
sys 0m 0.01s
We can see, that x86 stdatomic made execution 3-5 times slower. The code generated by ARM compiler slowed down 7-8 times. Surprisingly, the main bottleneck in the generated code was dmb sy instruction. Removing it, gives synchronized code, which executes only 1.5-2 times slower than non-synchronized! The question is if removing memory barriers is 100% bullet-proof.
I hope you are not sleepy after reading this post :). If you have any suggestions regarding this series, or you have some remarks, please add a comment. Next time I will try to compile something similar in typical embedded architecture, which is AVR.
My favorite C11 feature is the support of atomic operations. It is useful, especially on embedded systems, where using mutexes is very often overkill. At this point, in many circumstances, we can put away platform-dependent, error-prone, and not-effective synchronization API and easily use variables from different contexts. Of course, not every operation is possible. But if something is not possible, it is probably caused by poor software design. Let’s see how it works on typical architectures.
I will run 2 threads using pthread native library and show how assembly is build to make presented operations atomic. The example is typical, placed in every book about multithread-programming.
#include <stdatomic.h>
#include <pthread.h>
#include <stdint.h>
#include <stdio.h>
int32_t x = 0;
void * Thread(void * arg);
int main(void)
{
pthread_t t;
pthread_create(&t, NULL, &Thread, (void*)1);
Thread((void*)0);
pthread_join(t, NULL);
printf("%d\n", x);
return 0;
}
void * Thread(void * arg)
{
for (int i = 0; i < 1000000; ++i)
{
if (arg)
x++;
else
x--;
}
return NULL;
}
I think the code is self-explanatory. The only thing is the dirty passing of boolean value by the pointer. I know it’s not elegant, but it takes less coding. The output expected by synchronization-ignorant is 0. But of course, it is not:
Let’s see how stdatomic handle this situation on my native compiler. I’ve made similar code with the only difference of using stdatomic library and type supported by it:
Now our results are surprisingly correct – with no locks, mutexes, etc. Let’s see what kind of magic is done behind it.
x86-64
The test in this part of the article series was performed on the native architecture of my laptop (gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0). It produces the following assembly output for our program.
The most interesting is the implementation of Thread function. So I pasted only this one. It has a few parts:
.LFB6: – variables initialization, not interesting
.L5 and.L7 – this is our for loop. L7is ivariable incrementation.
.L8 and .L6 – is ifstatement and its content. .L8 after je instruction implements if (arg) branch. L6 implements else branch.
The most crucial are these two assembly snippets:
movl $1, -28(%rbp) # move 32-bit value "1" to memory[%rbp-28]
movl -28(%rbp), %eax # load this memory to %eax register
lock xaddl %eax, x(%rip) # this instruction does the job (fetch-and-add with lock prefix)
movl $1, -20(%rbp) # as above memory[%rbp-20]
movl -20(%rbp), %eax # as above
negl %eax # make negation of %eax to decrement variable i
lock xaddl %eax, x(%rip) # as above
So, the usage of stdatomic library forced the compiler to utilize lock xaddl instruction, which allows atomic incrementation. lock is x86 feature, that blocks cache line for whole instruction. Keep in mind, that this, like any kind of synchronization, has an impact on performance. Let’s see how code is built without stdatomic.h library. I will paste only the essential part:
As you can see. The code similar, but there is no lock xaddl instruction. Incrementation is done in three standard steps (load movl, increment addl, and store movl). Which are not atomic nor synchronized.
In the next chapter, I will focus on stdatomic with ARM architecture.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.